Warning: Undefined variable $PHP_SELF in /customers/9/8/1/usmart.dk/httpd.www/bachelor/index.php on line 2
Warning: Undefined array key "word" in /customers/9/8/1/usmart.dk/httpd.www/bachelor/index.php on line 5
Warning: Undefined array key "svar" in /customers/9/8/1/usmart.dk/httpd.www/bachelor/index.php on line 6
Warning: Undefined array key "valg" in /customers/9/8/1/usmart.dk/httpd.www/bachelor/index.php on line 7
Spanners
Finding the nearest neighbour in a cone can be done by brute force, simply by computing all distances between the given vertex, p, and vertices between the rays making up the cone. With n vertices this is O(n2) computations. This section will outline a more efficient method.
Construction of the Θ-graph can be optimized using a combination of geometry and underlying data structures. These 'tricks' are simple individually, but their combined use may seem complex. In this section they will be introduced one by one.
Ordering vertices by rays
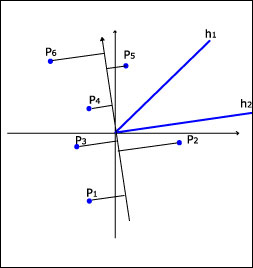
A cone is defined by two rays, h1 and h2, emanating from a vertix p. To be able to tell which vertices lie inside the cone, it is convenient to know how the vertices are ordered with regard to these rays.
To do so, a directed line, D2, orthogonal to the ray h2 and directed towards the side of h2 containing the cone, is constructed. All vertices are then projected orthogonally onto D2. These projections, along with the direction of D2, define an ordering of the vertices formally known as the order induced by D2. All vertices following p in this ordering are on the 'right' side of h2, that is, the side containing the cone.
Figure 9: The order induced by D2
The set S = {p1, ... , pi, pj, ... , pn} is ordered so pj-n are on the 'right' side of the ray h2 emanating from pi.
A similar, mirrored procedure is performed with the other ray defining the cone. The vertices lying on the 'right' side of both of these rays are in the cone, and thus candidates for the nearest neighbour. In this way the candidates for nearest neighbour in a cone among n vertices can be found in O(n) time.
Note, that the orderings need only be computed once for each cone, since it is the same for all vertices.
Approximating the nearest neighbor
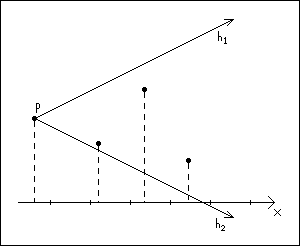
Imagine a cone, the center of which is aligned with the x-axis. Now we simply select the vertice with the smallest x-value higher than that of p.
Notice that this is an approximation of the nearest neighbour. There may be neighbours with a shorter euclidian distance to p, but in this algorithm the approximation will suffice.
Figure 10: Nearest neighbor
Approximating the nearest neighbour in a cone by examining x-coordinates.
The precondition is, that the center of the cone is aligned with the x-axis. If this is not the case, the vertices can be translated to make it so. This translation can be done in O(n) time.
Finding a nearest neighbour in this way is done in O(n2), since for every candidate fitting the criteria for h1, it must also be checked if it fits those of h2. Luckily, a datastructure exists to speed up this process.
Binary search tree
One of the datastructures used is a balanced, binary search tree. The search tree is to be used as a fast way to find the nearest neighbor. That is, the vertice above some halfplane, and below another, with the smallest x-value. For increased performance every node of the search tree contains information about which vertice in the sub-tree have the smallest x-value.
Constructing this tree can be done in O(n·log n) time.
When the search tree sort vertices in the order induced by D2, the elements in a left sub-tree are on the 'wrong' side of the ray h2. That is, they can not be candidates for nearest neighbor. Thus, when the tree is traversed from the top to a vertice p, each time a left sub-tree is chosen along the way, the right sub-tree contains (at least) one candidate.
Since nodes of the tree contain information about which vertice in the sub-tree have the smallest x-value, only the O(log n) nodes in the right sub-trees need to be compared to find the right candidate. Comparison of O(log n) elements can be done i O(log n) time, making this the complexity of a search in the tree.
The Trick!
A balanced, binary search tree, sorting vertices by the order induced by D2, is constructed. In this tree, the vertice on the 'right' side of h2 with the lowest x-value can be found in O(log n) time. For now the tree is empty.
Vertices are then inserted one by one in reverse order of the order induced by D1. This ensures, that when a vertice is inserted, all of the vertices allready in the tree are on the 'right' side of h1. After inserting a vertice, the tree is traversed to find its nearest neighbor. This neighbor (if one is found) is on the 'right' side of both h1 and h2, and thus in the cone.
When all vertices have been handled, the edges of one cone have been found for all vertices.
Complexity
Combined, the above algorithms and data structures make it possible to add the appropriate edges in one cone for all vertices in O(n·log n) time. Adding the edges in all κ cones can thus be done in O(κ·n·log n).
At this site you will find a slide-show illustrating the above adding of the edges for a cone in the Θ-graph.